Update 2018.04.13. Az utóbbi napokban valaki rongyosra olvasta ezt a posztot Veszprémből. Könyörgöm, ha ennyire érdekel, írj [erdeszpolitikus kukac gmail pont com], beszéljük meg. Nagyon szívesen válaszolok.
***
Összeraktam egy módszert, amivel ortofotókon automatikusan felismerhetők és lehatárolhatók az erdőfoltok (faállományok). Még nincs kész, de azon már túl van, hogy nagyon ígéretesnek mondjam.
Az utóbbi 10 évben fokozatosan világossá vált, hogy az országban a FÖMI nyerte meg a térinformatikát, azt a versenyt, hogy kinek lesz pénze adatgyűjtéseket végezni (légifényképeket készíteni) és know-howt felhalmozni. Gyakorlatilag egyeduralkodók lettek ezen a kulcsterületen. Aktuális ortofotókat a FÖMI készít Mo-on, és az EU-s területalapú támogatások adminisztrációjához felállított MePAR rendszerhez használja őket elsősorban, de egyéb célra megvásárolhatók és online is elérhetők. A teljes országos anyag ára meghatározhatatlan, mert így egyben nem vett még meg senki, egyetlen intézmény sem, de a területegységre adott ár alapján olyan 100-200 millió forintra tehető.
Az erdészeti igazgatásban használt MePAR-ortofotók, amikhez én is hozzáférek:
- valódi színesek (RGB, infra-csatorna nélkül),
- pixelméretük 40×40 cm (minden eddiginél jobb felbontásúak),
- vegatációs időben készültek (zöldellő növényekkel borított a táj),
- EOV-szelvényenként férhetők hozzá (4099 db, egyenként 4×6km-t lefedő kép),
- a korábbiakhoz képest meglehetősen egységes tónusúak (tehát a FÖMI-ben képmanipulációs eljárásokkal megoldották a különböző légifényképek eltérő színeinek összedolgozását),
- elképesztően részletgazdagok, az egyes fák kis bolyhos koronái külön látszanak, nagyon szépek.

Úgy voltam vele, hogy a faállományok automatikus felismerése lehet, hogy nem sikerül, de lesülne a bőr a képemről, ha meg sem próbálnám.
A módszernek semmilyen általam ismert előzménye nincs, nem olvastam utána, hogy ilyen felbontású fotóanyagból csináltak-e erdő-felismerést korábban mások. Felszínes tájékozódásom alapján a jelenlegi trend inkább a mintázat-felismerés felé húz.
Az egész eljárás adatbázis-kezelő szoftveren fut, hiszen csak matek; mindössze a térbeli összerendeléseket illetve az eredmények vizuális ellenőrzését és demonstrációját végeztem közönséges térinformatikai alkalmazásokkal (ArcView, QGIS).
1. Csempék
Osszuk fel az EOV-szelvényt (az ortofotót) csempékre (egyforma négyzetekre). A csempe legyen:
- 50×50 pixel, azaz 20×20 méter nagyságú (nagyjából egy fa koronavetületének megfelelő méret, és 20 méter a FAO szerinti erdődefinícióban is az erdőfolt minimális szélessége - egy fányi széles, magyarán),
- területe 400nm (ami megegyezik a fásítások méretének alsó határával a földhivatali tulajdon-nyilvántartásban),
- 60ezer csempe van egy szelvényen,
- az RGB-csatornák színintenzitás-eloszlásáról 3db hisztogram vezethető le (a vízszintes tengelyen a szaturáció 0-255 közötti).
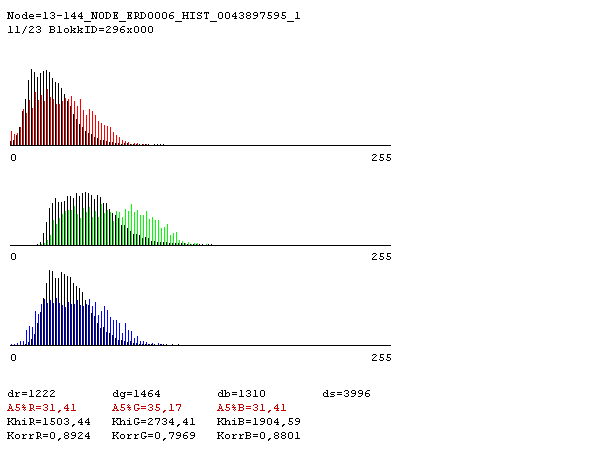
Más méretet is lehet választani, és majd ki is fogok próbálni más csempeméreteket is, de főleg amiatt kezdtem el 50×50 pixellel dolgozni, mert az egyes fák koronamérete közel ekkora, pontosabban ennél nem nagyobb. Eddig érdemes lefelé menni, ebben a méretben ragadhatók meg az erdőborítás meghatározó képi tulajdonságai, illetve más vegetációs formáktól való különbözősége. Kisebb méretben (pl. 5×5 pixelen) minden hasonló vegetációtípus hasonlóan néz ki: zöld. A nagyobb méret pedig rontaná az eredmény felbontását.
A 3 hisztogram a mintázaton kívül (tehát attól eltekintve, hogy az egyes pixelek milyen elrendezettségben vannak a csempén), minden képi információt hordoz a csempéről. Afféle ujjlenyomatai a vegetációnak, és további előnyük, hogy matematikailag jól kezelhetők.
2. Miben különböznek más felszínborítási formák az erdőtől a képen?
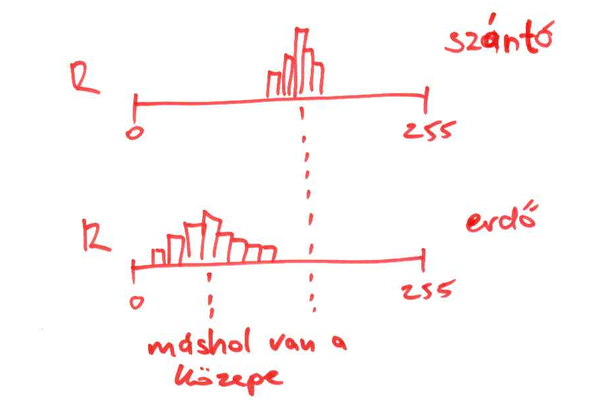
Pl. a szántók (egyes, bizonyos növénykultúrákkal fedett vagy éppen poros szántók) egészen más színűek. Ami a hisztogramokon úgy ragadható meg, hogy az eloszlások középértékei máshol vannak.
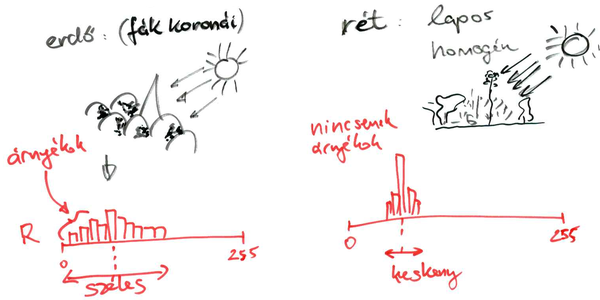
Pl. a rétek ugyanolyan zöldek, mint az erdő; de egy rét lapos, és nincsenek rajta árnyékok, míg a fák koronái egymás mellett egy hepehupás felületet adnak, a fák koronái egymásra árnyékokat vetnek, ami a hisztogramokon úgy látszik, hogy az erdőnél sok a sötét tónus, és a hisztogram emiatt szélesebb.
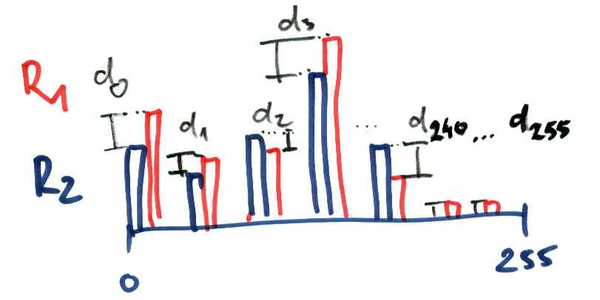
3. Hisztogramok összevetése
Két hisztogram összehasonlítható, ha egymásra teszed őket. A hasonlóság pedig számszerűsíthető is az egyes intenzitás-értékekhez (0-255) tartozó oszlopmagasságok összevetésével. A két hisztogram ilyenkor két darab, egyenként 256 attribútumot hordozó objektumként tekintendő, s rájuk valamilyen távolságfüggvényt kell alkalmazni.
A szakirodalomból megismerhető távolság-függvények közül kettő vált be:
- a korrelácia (COR, a klasszikus, két változó kovarianciájára épülő statisztikai mérőszám, lásd Podani p89, 3.70);
- a hasonlóság-index (SIM, similarity-ratio, lásd Podani p89, 3.71, és a mester sem említi az eredeti szerzőt).
A COR [-1..+1] tartományban, a SIM [0..+1] tartományban méri a hasonlóságot. Mindkettőre igaz, hogy ha a hasonlóség 1, akkor a két hisztogram teljesen azonos; és minél inkább különbözik a két hisztogram, annál inkább különbözik a hasonlóság mértéke 1-től.
4. Prototípusok
Az Országos Erdőállomány Adattárban nyilvántartott erdők elhelyezkedése és tulajdonságai (pl. faállomány-típus, záródás, kor stb.) ismertek, és az egyes szelvényeken minden egyes csempéhez hozzárendelhetők. Az egyes erdőrészletek homogén foltjaira eső csempéinek halmazához hozzárendelhető 3-3 átlagos hisztogram, ezzel az adott állományszerkezetre jellemző prototípusok jönnek létre.
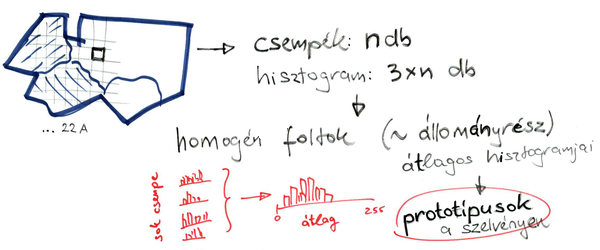
A homogén foltok azonosítását egy klaszterezési eljárással végeztem, ami hasonlít az UPGMA-módszerhez, de a végén a csoportképzés, pontosabban az eredményül kapott csoportok elfogadása azok belső homogenitása alapján történik. Azok a foltok lesznek jók prototípusnak, melyek csempéi hasonlítanak egymásra.
A homogén foltok egyébként az erdőleírás korábbi "állományrész" fogalmával rokon valamik.
Egy szelvényen nagyjából 0-300 erdőrészlet fordul elő, átlagosan 70-100 darab. Homogén folt vagy állományrész részletenként 1-3 féle szokott lenni, tehát szelvényenként pár száz prototípust kell kezelni.
A prototípusok elvileg más referencia-adatokból (faállományok terepi megfigyeléséből) is levezethetőek lennének, pl. a szisztematikus erdőleltár (EEM) mintapontjaiból, de ezekhez az adatokhoz egyelőre nem férek hozzá.
5. Osztályozás
Menjünk végig a szelvény összes csempéjén, és minden egyes csempéjét hasonlítsunk össze minden egyes prototípussal. Az adott csempe ahhoz a prototípushoz rendelhető, amelyik prototípushoz mért hasonlósága a legnagyobb. És ha a csempe hisztogramjai hasonlítanak egy prototípushoz, akkor úgy is néznek ki, továbbá feltételezhető, hogy a csempén olyan faállomány van, mint a prototípusé.
6. Eredmények
Az első tesztek alapján jól működik, várakozásokon felül jól.
Elválik a rét az erdőtől.
Megtalálja a házak közt a szoliter fákat.
Viszont elvéti a zöld csíkos szántót (talán kukoricás lehet).
Jelenleg fix >=0,80 hasonlóság felett tekintek erdőnek egy csempét, tehát ha van olyan prototípus, amihez mért hasonlóság ennél nagyobb, akkor az erdő. De ez nagyon kezdetleges threshold, és fejlesztésre szorul.
Eddig csak a vörös (R) csatornát használtam az osztályozáshoz, de a vegetációra vonatkozó információ a zöld csatornán is sok van, és lehet, hogy végül a 3 csatorna valamilyen lineáris kombinációját vagy főkomponensét kell majd alkalmazni.
Az alapokat így is tudja.

Eddig kb. 150 munkaóra van a fejlesztésben, és eddig 1 szelvényen kísérleteztem (13-144 szelvényszámú, Somogyban van, Patapoklosi nevű falu környéke, lásd fent).
7. Perspektívák
Továbbmenve: elvileg bármilyen felszínborítás felismerhető, nem csak az erdő, ha prototípusok gyárthatók hozzá.
Az erdővel az a szerencse, hogy az Adattár személyében nagyon nagy területi lefedettségű minta áll rendelkezésre, és ez a tanulóterület pontos koordinátákkal lokalizált is. Jelenleg a csempéket az EOV-szelvényen belül fellelhető prototípusokkal vetem össze, de elvileg, ha az ortofotók valóban egyformák, azonos tónusúak, akkor nincs akadálya annak, hogy a szelvényen kívüli prototípusokat is használjak.
A prototípusokon keresztül minden csempéhez faállomány-leírás rendelhető, az erdő területén és elhelyezkedésén túl minden olyan leíró statisztika előállítható, ami a referencia-adatokban megvan (pl. fakészlet). Ha az Adattárat használjuk referenciának (= az Adattárból gyártom a prototípusokat), a módszer az Adatáron kívüli faállományokat azonosítja. Ha a szisztematikus leltárból indulok ki, mely sokkal kisebb területi lefedettségű mintát jelent, a feladat az erdőborítás térképének előállítása (lásd többforrású erdőleltár). De mindkét esetben az országos teljes erdőállomány leírására a cél, a csempéknek megfelelő területi felbontásban.
A precíz erdőtérkép levezetéséhez az eredményből ki kell maszkolni a nem-erdő fás vegetációkat (pl. gyümölcsösök). Továbbá az eljárás gyorsítására ki lehet maszkolni a biztosan nem-erdő területeket (pl. belterületek, utak, nagy vizek stb.). Azután szűrni kell az egész csempe-halmazt, mert pl. az erdődefiníciók kikötik, hogy az erdőfolt minimális mérete fél vagy egy hektár legyen, és be lehet foltozni a túl kis lékeket az erdőterületen belül - de ezek mind rutin térinformatikai feladatok, amikhez innováció nem nagyon kell, csak megfelelő alapadatok.
***
Köszönet Tóth Gábornak, aki lekódolta nekem C#-ban az ortofotók pixeleinek felolvasását, illetve a csempénkénti hisztogramok és alapstatisztikák legyártását. Az általam használt szoftverben csak olyan lassú megoldást lehetett kiizzadni, ami agyonvágta volna az egész projektet.
Köszönet Benedek Gábornak sokrétű támogatásáért.
Irodalom:
Podani János: Bevezetés a többváltozós biológiai adatfeltárás rejtelmeibe (Scientia Kiadó, Budapest, 1997, ISBN 963 8326 06 9)