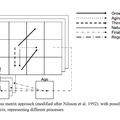
Az osztályozást tehát jó lett volna megoldani automatizálva. Ehhez nem találtam megfelelő klaszterezési eljárást az általam ismert szoftverekben és a rendelkezésre álló pár nap alatt. Olyan osztályozási eljárást, ami:
- eleve létező csoportokat (elemi erdészeti tájrészleteket) tud osztályozni, azaz eloszlásokat osztályoz;
- elválasztja őket az átlagaik alapján;
- kis számú csoportot képez (2-3-4 darabot).
Biztos van ilyen, nem hiszem, hogy a statisztika tudományában fel lehetne találni a spanyolviaszkot, de én pár nap keresgélés után sem találtam ilyet.
Ezért írtam egyet.
A varincia-analízisben a csoportokon belüli és a csoportok közti variancia viszonyát hasonlítják össze. Ezzel mérhető az átlagok eltérése. E csoportosító eljárásban pedig az a cél, hogy olyan csoportokat képezzek, ami minimalizálja a csoportokon belüli variancát és maximalizálja a csoportok közöttit.
A legjobb az lenne (brute force megoldás), ha minden lehetséges 2-3-4 db csoportot eredményező csoportosítási kombinációt meg lehetne vizsgálni, csoporton belüli varianciákat számolni és a legjobbat kiválasztani. De sajnos 92 db erdészeti tájrészletből bődületes számú kombinációban lehet 2-3-4 csoportot képezni, ezért ez nem megoldható.
Olyan megoldást választottam, hogy az algoritmusnak megadtam jellegzetes tájrészleteket, amik egyrészt nagy területűek (a fatermőképesség fafajsori területtel súlyozott varianciája szoros összefüggésben van a területtel, általában a nagy területű tájak dominálnak egy-egy csoportot), másrészt a képzendő csoportokat reprezentálják. Azaz nagy és átlagukban markánsan különböző tájrészleteket választottam ki, 2 vagy 3 darabot. Az algoritmus ezekhez a magokhoz illeszti a többi tájrészletet.
A variancia implicite tartalmazza az ftk-átlagok viszonyait. Annál illesztésnél növekszik a legkevésbé a variancia, ahol az új belépő tájrészlet átlaga a legközelebb van a már létező csoport átlagához, illetve ami kicsi elemszámú.
Tegyük fel, hogy 2db mag van, azaz két csoport képződik.
Az algoritmus az első lépésben hozzápróbálja a magokhoz az összes még be nem sorolt tájrészletet. Minden maghoz kiválasztható az, ami a legkevésbé emeli meg a varianciát a mag-egtáj belső varianciájához képest. Aztán ki kell választani azt a magot, ahol a legkevésbé emelkedett a variancia. Így egy tájrészletet besoroltunk.
A következő lépcsőben van egy 2 elemű csoport és egy 1 elemű. Ezekhez újra hozzápróbálja az összes szabad tájat, mindkét magnál kiválasztja azt, ami a legkevésbé emeli a csoport varianciáját; majd azt a magot, aminél kevésbé emelkedett a variancia.
És ezt így tovább mindaddig, amíg el nem fogy az összes besorolandó tájrészlet.
Kicsit hasonlít a k-means clusteringre, de nem ugyanaz.
Ez az eljárás először a mag körüli kis tájakat gyűjti oda majd, aztán a rizikósabb nagyobb tájak sorsa eldől magától.
Praktikusan akkor jó az osztályozás, ha a képzett csoportok:
- elég nagyok (terület), hogy kerüljön majd beléjük kellő mennyiségű FNM-mintapont, amivel stabil regressziós modelleket lehet szerkeszteni;
- az átlagaiknak elég távolnak kell lenniük, hogy a csoportok elváljanak egymástól (szerintem legalább ftk=2 m3/ha/év különbség, az már 1-2 fatermési osztályt jelent a hagyományos, egyenletes osztásközű fatermési tábláknál).
Az osztályozás jóságát a csoportokon belüli és a csoportok közötti variancia viszonyával lehet mérni. Minél nagyobb a csoportok közti variancia, annál szeparáltabbak a csoportok. Minél kisebb ez a szám, annál inkább összemosódnak a csoportok. A csoportok közti variancia általában a sokaság teljes varianciájának 25-30%-át adta: kb. ennyit javít az osztályozás a későbbi eredmények pontosságán [ez nem pont jó kifejezés].
|
1 |
KST |
Csoportok közti variancia: 34,1% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
13 |
10,230 |
145 516,7 |
42 313,45 |
|
|
|
Node 2 |
45 |
8,436 |
201 616,3 |
27 907,25 |
|
|
|
Node 3 |
34 |
6,402 |
133 491,9 |
50 508,66 |
|
|
|
Megj: a középső csoportot el lehet hagyni, az a legkisebb területű. |
||||
|
|
|
|
|
|
|
|
|
|
|
Csoportok közti variancia: 27,2% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
36 |
9,660 |
282 358,5 |
71 427,54 |
|
|
|
Node 2 |
56 |
7,053 |
248 435,9 |
49 374,12 |
|
|
|
Megj: a 3-as besorolás középső csoportjának elhagyásával. |
||||
|
|
|
|
|
|
|
|
|
2 |
KTTm |
Csoportok közti variancia: 33,2% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
38 |
13,403 |
150 906,6 |
33 185,53 |
|
|
|
Node 2 |
54 |
10,156 |
342 599,6 |
62 321,94 |
|
|
|
Megj: 3-as csoportosításnál a leggyengébb csoport (átlag = 7,986) nagyon kis területet adott (2400 ha). |
||||
|
|
|
|
|
|
|
|
|
3 |
KTTs |
Csoportok közti variancia: 28,6% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
33 |
11,814 |
80 576,0 |
15 697,88 |
|
|
|
Node 2 |
59 |
8,346 |
308 169,1 |
74 425,38 |
|
|
|
Megj: 3 csoportnál a legjobb (átlag = 13,568) nagyon kis területet adott (4800 ha). |
||||
|
|
|
|
|
|
|
|
|
5 |
CSm |
Csoportok közti variancia: 35,8% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
36 |
9,599 |
63 110,1 |
34 913,51 |
|
|
|
Node 2 |
55 |
7,394 |
138 664,7 |
68 444,55 |
|
|
|
Megj: 3 csoportnál nem volt túl nagy különbség a két rosszabb közt (8,866 - 7,226). |
||||
|
|
|
|
|
|
|
|
|
6 |
CSs |
Csoportok közti variancia: 26,7% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
34 |
7,872 |
30 849,7 |
12 740,66 |
|
|
|
Node 2 |
40 |
5,587 |
112 182,3 |
45 545,19 |
|
|
|
Megj: Nem érdemes harmadik csoportot csinálni, csak 1000 ha tervezett terület jutna a legjobbak közé. |
||||
|
|
|
|
|
|
|
|
|
7 |
B |
Csoportok közti variancia: 24,1% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
29 |
10,647 |
62 448,0 |
25 470,95 |
|
|
|
Node 2 |
33 |
8,625 |
167 185,1 |
60 070,77 |
|
|
|
|
|
|
|
|
|
8 |
GY |
Csoportok közti variancia: 44,1% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
12 |
7,049 |
45 831,3 |
14 016,17 |
|
|
|
Node 2 |
44 |
4,674 |
85 626,9 |
33 491,86 |
|
|
|
Node 3 |
32 |
2,874 |
150 208,2 |
60 847,91 |
|
|
|
Megj: itt pont nem vártam volna, hogy érdemes 3 csoport csinálni, de szeparálódik. |
||||
|
|
|
|
|
|
|
|
|
|
|
Csoportok közti variancia: 34,8% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
34 |
6,042 |
113 372,1 |
29 724,89 |
|
|
|
Node 2 |
54 |
3,187 |
215 133,7 |
78 631,05 |
|
|
|
Megj: A középső csoport elhagyásával. |
|
|
|
|
|
|
|
|
|
|
|
|
|
9 |
Am |
Csoportok közti variancia: 21,6% |
Tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
34 |
11,667 |
259 017,9 |
23 531,41 |
|
|
|
Node 2 |
58 |
8,221 |
335 232,0 |
33 152,08 |
|
|
|
|
|
|
|
|
|
10 |
As |
Csoportok közti variancia: 27,2% |
Tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
34 |
11,912 |
612 087,8 |
53 270,63 |
|
|
|
Node 2 |
58 |
7,993 |
772 835,5 |
92 036,27 |
|
|
|
|
|
|
|
|
|
13 |
HNY |
Csoportok közti variancia: 26,0% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
21 |
13,374 |
141 061,7 |
12 723,11 |
|
|
|
Node 2 |
71 |
9,339 |
230 643,3 |
21 562,62 |
|
|
|
|
|
|
|
|
|
15 |
MÉ |
Csoportok közti variancia: 10,9% |
Tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
21 |
9,248 |
76703,2 |
19537,74 |
|
|
|
Node 2 |
65 |
7,688 |
73306,9 |
12349,13 |
|
|
|
Megj: nem érdemes csoportokat csinálni, nincs számottevő variancia a csoportok közt (10,9%). |
||||
|
|
|
|
|
|
|
|
|
17 |
EF |
Csoportok közti variancia: 19,1% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
22 |
9,465 |
62 360,1 |
38 426,23 |
|
|
|
Node 2 |
69 |
8,166 |
94 932,4 |
51 453,13 |
|
|
|
Megj: ez a leggyengébben elváló csoportosítás, kicsi a különbség a két átlag között, nem vagyok biztos benne, hogy egyáltalán érdemes-e csoportokat képezni. Nem, nem érdemes. |
||||
|
|
|
|
|
|
|
|
|
18 |
FF |
Csoportok közti variancia: 9,7% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
43 |
7,618 |
9187,3 |
4091,41 |
|
|
|
Node 2 |
46 |
5,999 |
80431,9 |
36346,84 |
|
|
|
Megj: nem érdemes csoportokat csinálni, nincs számottevő variancia a csoportok közt (9,7%). |
||||
|
|
|
|
|
|
|
|
|
833 |
EH |
Megj: a terület és a variancia fele 531-ben (Nyugat-Zselic) van. A maradék ugyan gyengébb, mint a Nyugat-Zselic, de egyenként valószínűleg kevés mintapontot adnának. Nem érdemes csoportokat képezni. |
||||
|
|
|
|
|
|
|
|
|
631 |
MK |
Csoportok közti variancia: 22,4% |
tájrészlet db |
ftk átlag |
variancia |
terület |
|
|
|
Node 1 |
47 |
13,711 |
36 412,4 |
5 738,48 |
|
|
|
Node 2 |
44 |
10,621 |
90 138,0 |
11 501,62 |
|
|
|
Megj: le lehetne leválasztani a jobb termőhelyeket, de összesen 17ezer ha-ról van szó, tehát kevéssé valószínű, hogy lesz a kis csoportokhoz megfelelő számú mintapont. Nem érdemes csoportokat képezni. |
||||
Czirok István kolléga szakmai tapasztalatai és az előzetes hisztogramok alapján készített egy két csoportos (jobb-gyengébb) osztályozást az Akác mag táblára. Ezt kíváncsiságból összevetettem az algoritmikus eredménnyel. 92 tájrészletből 81 esetében azonos besorolásra jutottunk. A 11 darab eltérés a teljes vizsgálati anyag (a 2005-2014 közt átvezetett erdőtervek) fafajsori területének 4,6%-a. Sikerélmény. További önbizalomra ad okot.
Térképeken ábrázoltuk (Magyar Zsolt tette) a kialakult csoportosítást, és meglepően egybefüggő tömböket adott, és ami ki is válik a tömbökből, az indokolhatóan válik ki (pl. az árterek). Azt hittem, sokkal mozaikosabb lesz.
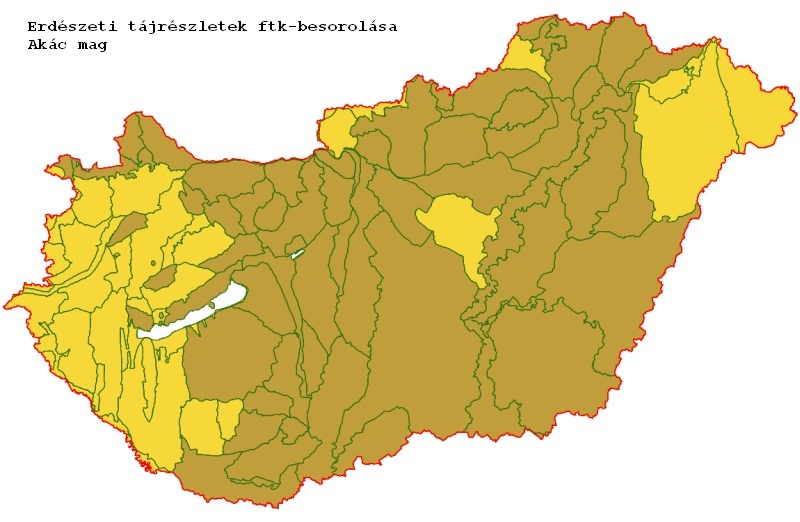
Szerintem többször az van, hogy amikor egy általában jó termőhelyekben gazdag tájon egy fafaj/fafajcsoport gyengébb eredményeket ad, ott általában a konkrétan jó részletekben az értékesebb fafajok vannak, és csak a gyengébb részletekben a betelepített faj (akác esetében volt ez a benyomásom).